
Эволюция текстового ранжирования: Как нейросети Яндекса и Google оценивают смысловую релевантность контента

Поисковые роботы давно перестали воспринимать текст как простой набор ключевых фраз. Понимание фундаментальных принципов работы текстовых факторов — обязательное условие для вывода сайта в топ. В этом материале мы разберем, как алгоритмы нового поколения анализируют контент, почему старые методы оптимизации ведут к пессимизации и как заставить поисковые системы высоко оценивать ваши статьи.
Для кого написан этот гайд?
- SEO-стратегам и оптимизаторам, стремящимся понять логику современных нейросетевых фильтров.
- Тимлидам и руководителям digital-агентств для контроля качества контентной оптимизации на проектах.
- Текстовым аналитикам и авторам семантических ТЗ, создающим ТЗ для копирайтеров в конкурентных коммерческих нишах.
1. Классические текстовые факторы против New-Gen моделей
Официальные рекомендации поисковых систем часто звучат просто: «Пишите естественные тексты для людей, забудьте про SEO». В идеальном мире, где алгоритмы полностью освоили обработку естественного языка (NLP), этот совет работал бы безупречно. Однако на практике поисковики всё еще используют гибридные модели, где классические математические формулы работают в связке с нейросетями.
Важно понимать: классическая текстовая оптимизация и новые текстовые факторы нового поколения (New-Gen) — это изолированные метрики. Высокие показатели в одной модели никак не компенсируют провалы в другой. Исторически поиск оперирует формулами типа TF-IDF и BM25 (а также их модификациями с весовыми коэффициентами), но логика их применения кардинально изменилась.
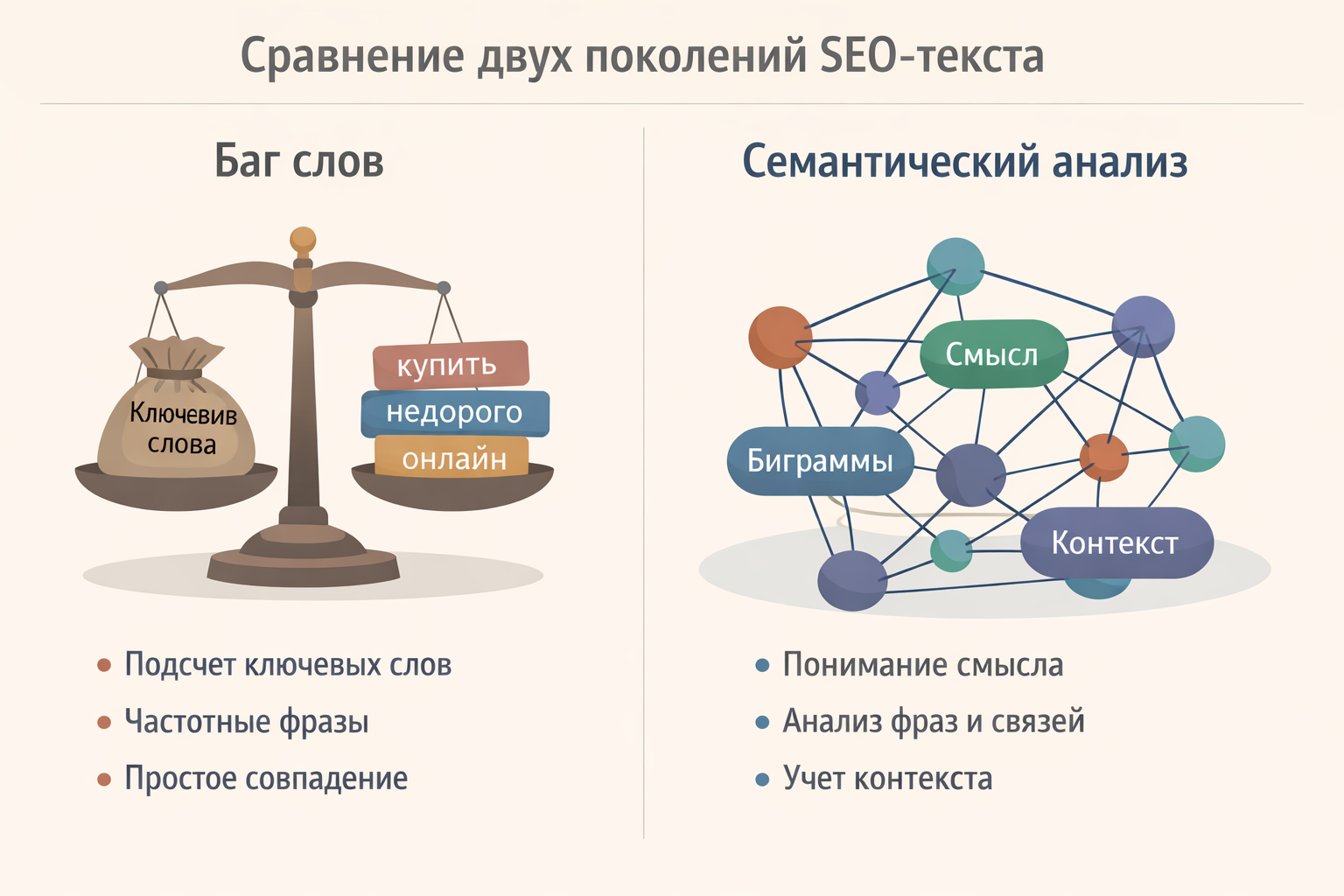
Традиционный подход: Концепция «мешка слов» (Bag of Words)
Суть классической модели максимально упрощена. Алгоритм условно «высыпает» все слова из текста в один мешок, перемешивает их и подсчитывает частоту вхождений. При таком подходе полностью уничтожается структура и архитектура текста. Поиск теряет два важнейших уровня данных:
- Информация о взаимном расположении слов и расстоянии между ними.
- Смысловая нагрузка слов, которые не входят в исходный поисковый запрос.
Даже использование синонимов в рамках этой модели работает со сбоями. Например, если протестировать в выдаче запросы «сотовый телефон» и «мобильный телефон», становится очевидно, что поисковые системы далеко не всегда считают эти лексемы абсолютно взаимно заменяемыми.
| Параметр сравнения | Классическая модель («Мешок слов») | Нейросетевые модели (DSSM / BERT) |
|---|---|---|
| Что анализируется | Только слова, входящие в поисковый запрос (и простейшие синонимы). | Абсолютно весь полезный контент страницы, включая сопутствующую лексику. |
| Учет структуры | Игнорируется. Порядок слов и связность текста не имеют значения. | Учитываются биграммы, триграммы и двунаправленный контекст предложений. |
| Принцип оптимизации | Попадание в строгий диапазон вхождений, высчитываемый анализаторами. | Насыщение текста тематическими паттернами, LSI-словами и маркерами интента. |
2. Эра семантического поиска: Модели DSSM («Палех» и «Королёв»)
Запуск алгоритмов «Палех» и «Королёв» ознаменовал переход Яндекса на семантическую модель глубокого структурированного анализа — DSSM (Deep Structured Semantic Model). Эта архитектура работает на принципиально ином уровне:
- Анализ полного объема данных: В отличие от «мешка слов», который отсеивал до 97% не входящего в запрос контента, DSSM оценивает буквенные триграммы, биграммы (пары слов) и отдельные словоформы по всей странице.
- Обучение на ассоциациях: Нейросеть целенаправленно обучали сопоставлять запросы пользователей с текстами веб-страниц, даже если они не содержат прямых ключевых слов.
- Выделение важного контента: Алгоритм пытается дифференцировать основные контентные зоны страницы от сквозных блоков, ориентируясь на внутренние маркеры релевантности.
Влияние на SEO-практику:
Огромная часть поисковых запросов в долгосрочной перспективе уникальна (низкочастотный «хвост»). Наблюдая за выдачей по таким запросам, можно заметить устойчивые текстовые паттерны в Title и текстовых блоках конкурентов. Внедрение этих скрытых тематических слов (даже если их нет в самом запросе) способно резко поднять страницу из ТОП-20 прямо в тройку лидеров.
3. Google BERT: Трансформеры и полноценный контекстный анализ
Алгоритм BERT (Bidirectional Encoder Representations from Transformers) стал важнейшей вехой на пути к полноценной обработке естественного языка (NLP) со стороны Google. Это архитектура принципиально иного уровня по сравнению с ранними нейросетями.
Ключевые особенности BERT:
- Двунаправленность (Bidirectional): Модель считывает и анализирует текст одновременно как слева направо, так и справа налево. Это позволяет улавливать тончайшие смысловые связи, предлоги и местоимения, полностью меняющие контекст фразы.
- Метод маскирования: В процессе обучения нейросети искусственно закрывали («маскировали») отдельные слова в предложениях, заставляя алгоритм угадывать их по окружающему контексту.
- Работа с интентом (Q&A): BERT великолепно справляется с поиском точных ответов на конкретные вопросы внутри объемных кусков текста, вычленяя суть без привязки к точным вхождениям ключей.
4. Как оптимизировать тексты в эпоху умных алгоритмов?
Старая стратегия («напиши текст с плотностью ключей 3%») гарантированно ведет к фильтрам за переоптимизацию (например, «Баден-Баден»). Современный подход требует гибкости:
- Использование текстовых анализаторов: Пытаться угадать необходимый объем и плотность слов «на глаз» неэффективно. Применяйте автоматизированные инструменты текстового анализа (например, модули в Just-Magic или Пиксель Тулс) для выявления необходимых биграмм и тематических паттернов на основе выборки текущих лидеров ТОПа.
- Расширение семантического поля страницы:Насыщайте Title, заголовки и основной текст сопутствующей лексикой, которая задает тематический контекст. Для коммерческих интернет-магазинов такими зонами могут стать блоки характеристик, товарные карточки и FAQ.
- Осторожная работа с кластеризацией: Правильная группировка запросов — фундамент продвижения. Современные кластеры могут объединять слова с минимальным количеством общих лексем (например, связанные только одним общим признаком), и продвигать их нужно на одной емкой посадочной странице, создавая широкое семантическое поле.
- Сложность деоптимизации: Из-за того, что нейросети учитывают сотни сопутствующих факторов, «снять» страницу с ранжирования по нерелевантному запросу простым удалением ключевого слова стало крайне тяжело. Проще адаптировать посадочную страницу под тот интент, который закрепил за ней поисковик.
5. Ответы на частые вопросы по работе текстовых алгоритмов (FAQ)
Как быстро поисковые роботы пересчитывают текстовые факторы после обновления страницы?
Этот процесс происходит достаточно оперативно. Базовое обучение нейросетей осуществляется на серверах поисковых систем заранее, поэтому сам прогон измененного или нового текста через готовую модель занимает минимум вычислительного времени. В Яндексе текстовые метрики учитываются практически сразу при обновлении поискового индекса по документу (за исключением факторов, требующих накопления длительной поведенческой статистики). В Google задержка после переобхода страницы роботом обычно составляет от 15 до 30 минут. Таким образом, расчет параметров занимает часы, а не недели.
По какому принципу работают алгоритмы автоматической кластеризации семантики?
Большинство специализированных инструментов на рынке работают по схожей математической модели: они анализируют пересечения URL-адресов в ТОП-10 выдачи по нужным запросам, а не проводят глубокий внутренний лингвистический анализ текстового контента. Если поисковая система выводит одни и те же сайты по разным фразам, алгоритм объединяет эти фразы в один кластер. Для оптимизатора это означает, что можно выбирать любой надежный инструмент, ориентируясь на удобство интерфейса, скорость обработки данных и тарифную сетку.
Существуют ли специфические механики оптимизации страниц конкретно под алгоритм Google BERT?
Отдельной изолированной механики оптимизации именно под этот алгоритм не существует, так как он является частью комплексной системы оценки качества. Стратегия продвижения здесь полностью совпадает с концепцией создания качественного контента для людей: необходимо логически структурировать документ, давать прямые и емкие ответы на сопутствующие вопросы пользователей, избегать размытых «водянистых» конструкций и максимально точно закрывать интент целевой аудитории.
Главные выводы
Нейросетевые алгоритмы Яндекса и Google совершили колоссальный шаг к полноценному пониманию человеческого языка, хотя до финальной точки NLP поиск еще не дошел. При создании контента критически важно уходить от прямолинейного закликивания ключами. Будущее SEO — за контентом, который максимально широко раскрывает тематику за счет использования правильных биграмм, текстовых паттернов, LSI-лексики и четко отвечает на интент целевой аудитории.